Retrieval
- Retrievers
- Vector stores
- Embeddings
- Text splitters
Some of the concepts reviewed here utilize models to generate queries (e.g., for SQL or graph databases). There are inherent risks in doing this. Make sure that your database connection permissions are scoped as narrowly as possible for your application's needs. This will mitigate, though not eliminate, the risks of building a model-driven system capable of querying databases. For more on general security best practices, see our security guide.
Introduction
Retrieval systems are essential in AI applications, enabling the efficient extraction of relevant data from extensive datasets. These systems support various data formats:
- Unstructured text (e.g., documents) is often stored in vector stores or lexical search indexes.
- Structured data is typically housed in relational or graph databases with defined schemas.
Modern AI applications strive to make all data types accessible via natural language interfaces. Models facilitate this by converting natural language queries into formats compatible with the underlying search index or database, allowing for more intuitive and flexible interactions with complex data structures.
Core Concepts
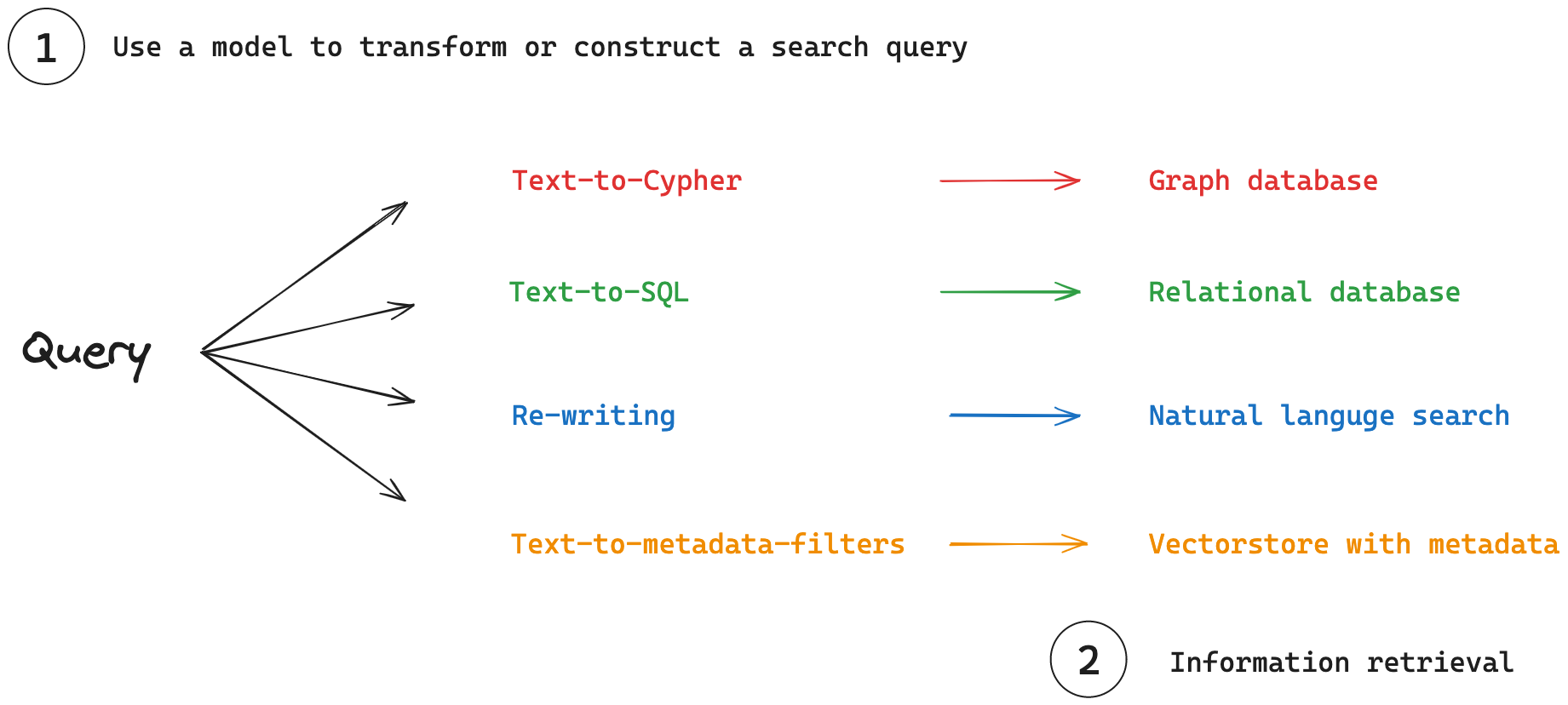
- Query Analysis: Models transform or construct search queries to optimize retrieval.
- Information Retrieval: Search queries are used to fetch information from various retrieval systems.
Query Analysis
Users generally prefer interacting with retrieval systems using natural language. However, retrieval systems may require specific query syntax or benefit from particular keywords. Query analysis bridges the gap between raw user input and optimized search queries. Common applications include:
- Query Re-writing: Enhancing queries for better semantic or lexical searches.
- Query Construction: Creating structured queries (e.g., SQL for databases).
Models transform or construct optimized search queries from raw user input.
Query Re-writing
Retrieval systems should handle a wide range of user inputs, from simple to complex questions. Models can transform raw user queries into more effective search queries, ranging from keyword extraction to sophisticated query expansion and reformulation. Benefits include:
- Query Clarification: Rephrasing ambiguous queries for clarity.
- Semantic Understanding: Capturing the intent behind a query.
- Query Expansion: Generating related terms or concepts.
- Complex Query Handling: Breaking down multi-part questions into simpler sub-queries.
Techniques for query re-writing include:
| Name | When to use | Description |
|---|---|---|
| Decomposition | When a question can be broken down into smaller subproblems. | Decompose a question into subproblems/questions, solved sequentially or in parallel. |
| Step-back | When a higher-level conceptual understanding is required. | Ask a generic step-back question about higher-level concepts, retrieve relevant facts, and use this grounding to answer the user question. Paper. |
| HyDE | If retrieving relevant documents using raw user inputs is challenging. | Convert questions into hypothetical documents, use these to retrieve real documents. Paper. |
Query Construction
Query analysis also involves translating natural language queries into specialized query languages or filters, crucial for interacting with databases that house structured or semi-structured data.
-
Structured Data: For relational and graph databases, Domain-Specific Languages (DSLs) are used.
- Text-to-SQL: Converts natural language to SQL for relational databases.
- Text-to-Cypher: Converts natural language to Cypher for graph databases.
-
Semi-structured Data: For vectorstores, queries can combine semantic search with metadata filtering.
- Natural Language to Metadata Filters: Converts user queries into appropriate metadata filters.
Techniques include:
| Name | When to Use | Description |
|---|---|---|
| Self Query | If questions are better answered by fetching documents based on metadata. | Transform user input into a semantic string and a metadata filter. |
| Text to SQL | If questions require information from a relational database. | Transform user input into a SQL query. |
| Text-to-Cypher | If questions require information from a graph database. | Transform user input into a Cypher query. |
Information Retrieval
Common Retrieval Systems
Lexical Search Indexes
Many search engines match words in a query to words in documents, known as lexical retrieval. This approach uses word frequencies, with an inverted index mapping words to document locations. BM25 and TF-IDF are popular algorithms.
Vector Indexes
Vector indexes store unstructured data using embedding models to compress documents into high-dimensional vectors, enabling efficient similarity search.
Relational Databases
Relational databases store structured data in tables with predefined schemas, using SQL for querying. They excel at maintaining data integrity and handling complex queries.
Graph Databases
Graph databases store interconnected data using nodes, edges, and properties, efficiently representing and querying complex relationships. They are useful for social networks, supply-chain management, fraud detection, and recommendation services.